在數字化時代,數據已成為企業決策與業務增長的核心驅動力。對于像鏈家網這樣的大型房產服務平臺,高效、精準的搜索與推薦系統是其用戶體驗和商業成功的關鍵。而這一切的背后,離不開強大的數據處理與存儲服務的堅實支撐。本文將探討鏈家網如何通過構建先進的數據處理與存儲體系,賦能其搜索優化與推薦策略,實現數據驅動的業務實踐。
一、數據處理:從原始數據到業務洞察
鏈家網每天產生海量的用戶行為數據(如搜索記錄、瀏覽軌跡、點擊偏好)、房源數據(如位置、價格、戶型、圖片)、交易數據以及外部市場數據。這些數據來源多樣、結構復雜、實時性強。數據處理服務的首要任務是將這些原始數據轉化為可供分析和模型使用的干凈、一致、高質量的數據資產。
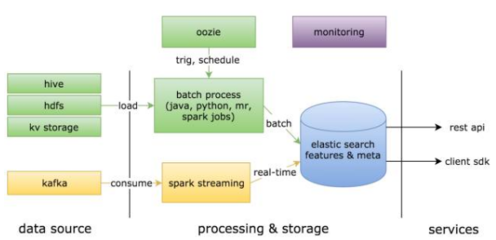
1. 數據采集與整合: 鏈家通過分布式日志采集系統(如Flume、Kafka)實時收集來自網站、APP、小程序等多端的用戶行為日志,并與內部的房源數據庫、交易系統等批量數據源進行整合,形成統一的用戶-房源交互數據集。
2. 數據清洗與標準化: 房產數據具有地域性強、字段多、非標信息(如戶型描述)多的特點。鏈家利用自然語言處理(NLP)和規則引擎對房源描述進行結構化提取(如將“南北通透三室兩廳”解析為明確的屬性),并對價格、面積等數值進行異常值檢測與校正,確保數據質量。
3. 實時與離線計算: 對于搜索排序和實時推薦,需要毫秒級響應用戶的最新興趣變化。鏈家構建了基于Flink等流計算引擎的實時數據處理管道,實時計算用戶的短期興趣標簽(如“正在關注朝陽區兩居室”)。利用Hadoop/Spark等離線計算框架,進行深度的用戶畫像構建(如長期偏好、購房能力評估)、房源質量分計算以及市場趨勢分析,為策略模型提供豐富的特征。
二、數據存儲:支撐靈活高效的訪問與服務
處理后的數據需要被高效、可靠地存儲,并支持高并發、低延遲的在線服務訪問,以及靈活的分析與模型訓練。鏈家采用了分層、混合的存儲架構。
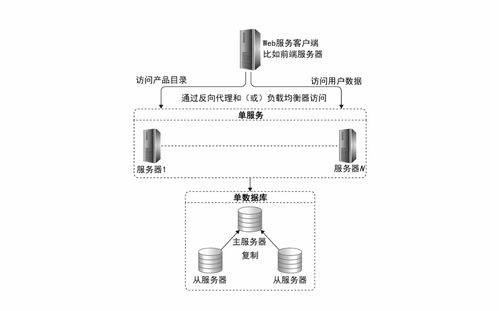
1. 在線服務存儲: 為了滿足搜索和推薦接口的極低延遲要求(通常要求在幾十毫秒內返回結果),鏈家將核心的特征數據(如用戶畫像向量、房源向量、熱門房源列表)存儲在Redis等內存數據庫中。將索引化的房源數據存儲在Elasticsearch中,以支持地理位置、多字段組合的復雜搜索與排序。關系型數據庫(如MySQL)則用于存儲交易、用戶賬戶等強一致性要求的核心業務數據。
2. 離線分析與模型訓練存儲: 海量的歷史行為數據、特征數據集以及模型訓練樣本,存儲在HDFS或對象存儲(如S3)中,為數據科學家和算法工程師提供大規模數據分析和模型迭代的“數據湖”。數據倉庫(如Hive)則用于存儲結構化的業務報表和指標數據,支持商業智能(BI)分析。
3. 特征存儲與管理: 為了避免特征計算邏輯在訓練和上線時的不一致(即“訓練-應用偏差”),鏈家構建了統一的特征平臺。該平臺將離線和實時計算產生的特征統一注冊、存儲和管理,確保搜索和推薦模型在線推理時,能夠從同一來源準確、快速地獲取所需特征。
三、驅動搜索與推薦策略
完善的數據處理與存儲服務,直接賦能了鏈家網搜索與推薦系統的智能化演進。
在搜索優化方面:
- 排序模型: 利用存儲的用戶歷史行為數據和豐富的房源特征,訓練深度學習排序模型(如LTR),以優化“相關性”排序,使結果更貼合用戶真實意圖,而非簡單的關鍵詞匹配。
- 查詢理解: 通過對海量搜索Query的NLP分析,識別用戶的潛在意圖(如“學區房”、“近地鐵”),并結合用戶畫像進行意圖消歧和結果擴展,提升搜索召回率和準確性。
- 個性化展示: 根據存儲在Redis中的實時用戶上下文,動態調整搜索結果頁的篩選器優先級或信息展示樣式。
在推薦策略方面:
- 多場景推薦: 基于統一的用戶畫像和房源畫像,為首頁信息流、房源詳情頁“猜你喜歡”、APP推送等不同場景構建實時推薦服務,實現“千人千面”。
- 協同過濾與向量化召回: 利用存儲在數據湖中的億萬級用戶-房源交互行為,訓練協同過濾模型和Embedding模型,將用戶和房源映射到同一向量空間,實現從十億級全量房源中毫秒級召回最相關的候選集。
- 探索與利用平衡: 通過實時記錄和存儲新上線房源或冷門房源的曝光與反饋數據,幫助推薦算法更好地平衡“利用”已知用戶偏好和“探索”新的潛在興趣,提升系統整體多樣性和用戶體驗。
###
對于鏈家網而言,搜索與推薦不僅是功能,更是連接用戶與房源的智能中樞。而這一切智能化能力的基石,是一套從采集、處理到存儲、服務的完整、高效、可靠的數據技術體系。通過持續投入和優化數據處理與存儲服務,鏈家網不僅提升了當前系統的性能和效果,更重要的是,積累了高質量的數據資產和敏捷的數據能力,為應對未來更復雜的業務場景和更智能的算法應用奠定了堅實基礎。數據驅動,在鏈家已從理念轉化為貫穿于數據處理、存儲到最終業務價值實現的完整實踐閉環。