在當今數據驅動的時代,面對海量數據和高并發訪問,單一數據庫往往難以支撐業務發展。MyCAT(My Cluster Abstract Technology)作為一款開源的分布式數據庫中間件,應運而生,旨在解決數據處理與存儲服務的擴展性、可用性和性能問題。本文將從核心概念、架構設計、應用場景和實戰要點四個方面,幫助你快速掌握MyCAT的精髓。
一、MyCAT的核心概念:數據分片與路由
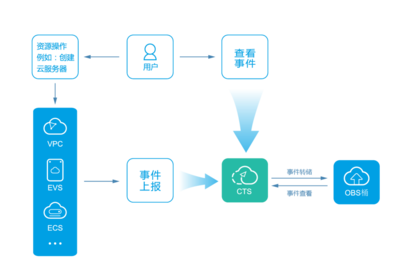
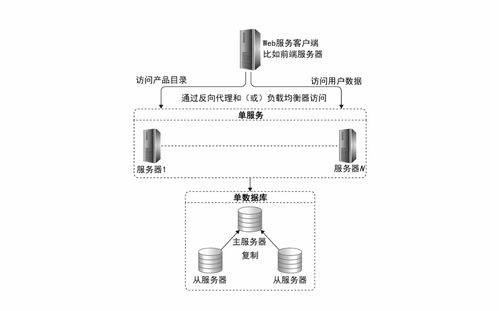
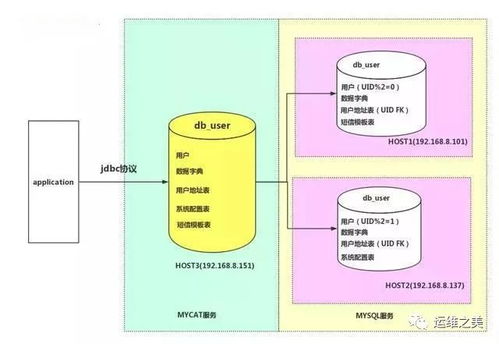
MyCAT的核心功能是數據分片(Sharding),即將一個大型數據庫表水平拆分成多個小表,分布到不同的數據庫節點上。它通過智能路由機制,將SQL請求轉發到正確的節點,對應用層透明。例如,用戶表按ID范圍分片,ID 1-1000在節點A,1001-2000在節點B。MyCAT還支持讀寫分離,將寫操作定向到主節點,讀操作分發到從節點,提升整體性能。
二、架構設計:邏輯庫與物理存儲的橋梁
MyCAT位于應用與數據庫之間,充當“代理”角色。其架構主要包括:
- 邏輯庫(Schema):對應用暴露的虛擬數據庫,如“user_db”,實際可能對應多個物理數據庫。
- 數據節點(DataNode):定義物理數據庫的連接信息,如MySQL實例。
- 分片規則(Rule):指定數據如何分布,如哈希、范圍或自定義算法。
- 全局序列(Sequence):解決分布式環境下的ID生成問題,確保唯一性。
這種設計使得開發者可以像使用單一數據庫一樣操作,而MyCAT在后端處理復雜的分布式邏輯。
三、應用場景:何時選擇MyCAT?
MyCAT特別適用于以下場景:
1. 高并發讀寫:如電商平臺,訂單表分片后,不同用戶請求可并行處理。
2. 大數據量存儲:日志或歷史數據超過單機容量,需水平擴展。
3. 讀寫分離需求:讀多寫少的系統,通過從節點分擔查詢壓力。
4. 多租戶架構:為不同租戶分配獨立數據節點,實現資源隔離。
需要注意的是,對于事務一致性要求極高或復雜關聯查詢頻繁的場景,需謹慎評估分片帶來的挑戰。
四、實戰要點:配置與優化指南
快速上手MyCAT需關注幾個關鍵步驟:
- 配置文件:編輯server.xml(服務參數)、schema.xml(邏輯庫與節點映射)、rule.xml(分片規則)。例如,在schema.xml中定義數據節點和分片表。
- 啟動與監控:通過命令行啟動MyCAT,利用管理端口(默認9066)查看連接狀態和性能指標。
- SQL優化:避免跨分片JOIN,盡量使用分片鍵查詢;利用MyCAT的緩存功能減少數據庫壓力。
- 高可用部署:結合Keepalived或ZooKeeper實現MyCAT自身集群,避免單點故障。
MyCAT通過抽象數據存儲層,為數據處理服務提供了靈活的擴展方案。掌握其分片、路由和配置核心,能有效應對數據增長帶來的挑戰。在實踐中,建議從小規模試點開始,逐步優化分片策略,從而構建穩健的分布式存儲體系。